
Data Lake vs. Data Warehouse: The Key Points Of Difference
Proper data storage is vital for all business organizations, especially the ones attempting to maximize value from the potential of Big Data. For any layman, data storage tends to be typically handled in a traditional database. However, when it comes to big data, modern firms use data lakes and data warehouses.
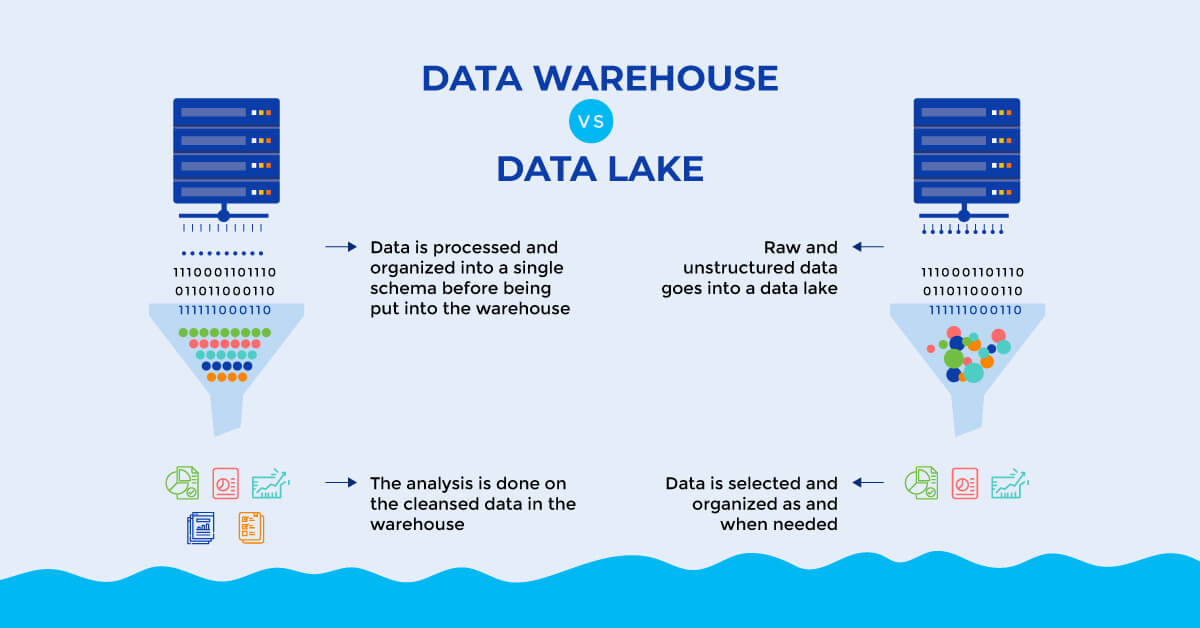
While both data lakes and data warehouses are extensively used for the purpose of storing big data, they are not interchangeable terms. A data lake is an expansive pool of raw data whose purpose has not been defined. This detailed source data is ideally built for algorithm-based analytics, such as statistics, data exploration, mining, and machine learning. While on the other hand, data warehouse implies to a repository meant for structured and filtered data which has been processed for set-based analytics like OLAP, reporting, and ad hoc queries. Understanding the difference between them is vital as they serve distinguished purposes, apart from their core function of acting as data storage.
The following pointers provide a better insight on the differences between data lakes and data warehouses:
- Data structure: raw vs. processed
Data lakes majorly store raw, unprocessed data, while refined and processed data is typically stored in data warehouses. Due to this, data lakes generally need a much greater storage capacity in comparison to data warehouses. The raw data present there is malleable, and hence can be analyzed swiftly for any reason, and is especially perfect ML. However, due to the high amount of raw data present, data lakes may face the risk of becoming data swamps that do not have adequate data quality and control measures in place.As data warehouses just store data that is processed, they save on quite a bit of storage space by not having to maintain data that might not be used anytime in the future. This processed data can moreover be understood with ease by a large set of audience.
- Purpose: undetermined vs. in-use
The key purpose of distinct data pieces present in a data lake is not fixed. While sometimes raw data that flows into a data lake are decided for a specific use, usually their purpose is not defined.Data warehouse features processed data that is meant to be used for a specific purpose in the organization.
- Accessibility: flexible vs. secure
Data lake architecture is quite easy to use, access, and change. Moreover, any changes made to the data can be done swiftly there, as the limitations are quite less in data lakes.Data warehouses are more structured by design, which makes data easier to decipher. This data, however, can be complicated and costly to change.
Are data lakes the future of data warehouses?
Data warehouses have been around for quite some time, and were the only way to store large amounts of data for reporting and analytics traditionally. Much like a physical warehouse, this data storage also has a rigid structure that is limited. To add more products to it, one may have to go through an expensive and extensive upgrade process. Data warehouses are also quite rigid in regards to handling the ever-changing data elements.
Data lakes are a much more modern take on big data. Similar to actual lakes, this storage also has a vast body and is able to expand, contract, and change over periods of time. They have the capacity to handle varying volume, velocity, and variety of data. The flexibility, speed, and accuracy of information coming out of data lakes help organizations to maintain better operational efficiency and provide for superior regulatory oversight.
Data lakes have, over the years, become the most common choice to handle complex data, especially with the increasing applications of AI and machine learning. There is an algorithm for almost everything today, right from using AI to clean and augment incoming data to running complicated algorithms for the purpose of correlating diverse sources of information in order to detect fraud. Through distributed processing, such algorithms can be run on multiple clusters, and its workload can easily be spread across nodes.
When building a data lake, one must be careful about not making it a data swap that cannot be properly controlled or navigated properly. One should progress towards developing their data lake based on what their ecosystem looks like and who their consumers are.