
Transforming the ‘Know Your Customer’ process using Optical Character Recognition
The advent of Artificial Intelligence (AI) has the potential to transform industries in a multitude of ways. Some born in the cloud unicorns and start-ups have embraced it with open arms. What about traditional and legacy industries like Banking and Financial Services? A lot of processes are still paper based and cumbersome, yet the industry is hesitant in adapting to newer technologies due to numerous concerns like effectiveness, change management and most importantly sensitivity of data. We’re attempting to change that. This blog outlines an architecture implemented at a prominent Indian Bank to digitize the first few steps in a KYC process. It describes how this solution addresses the business and compliance concerns of the industry and attempts to describe the limitations of this technology today.
The existing KYC process
The process encompassed various stages of human intervention and manual effort, including –
- Collection of relevant documents, like filled application forms and address proof, by an agent
- Submission of collected documents at the bank branch
- Scan and upload of hard copies into a Business Process Management (BPM) system
- Manual verification of image quality, visibility and validity
- Addition of tags and indices for type of document and checks to ensure submission of all types
- Manual data entry of all fields into a BPM module
- Validation rechecks and adherence to compliance requirements
The existing process involved at least five stages of manual checking before a customer’s KYC was processed. To eliminate indexing, quality checks and manual data entry, an OCR-based solution was envisioned.
OCR API
We used Microsoft OCR Version 2 API at the core of the architecture. OCR detects embedded, printed and handwritten text and extracts recognized words into machine-readable character streams. The API executes synchronously and is not optimized for large documents. The operation maintains the original line groupings of recognized words in its output. Each line comes with bounding box coordinates, and each word within the line also has its own coordinates. A demo for the same can be seen here. If a word is recognized with low confidence, that information is conveyed as well. If necessary, the API also rotates the images to detect text accurately.
Limitations of the OCR API
The OCR API works on images that meet the below requirements:
- Size of input image – Between 50 x 50 and 4200 x 4200 pixels
- File size – Less than 4 megabytes (MB)
Additionally, there are a few other limitations we observed:
- Rotation – Text can be rotated by any multiple of 90 degrees plus a small angle of up to 40 degrees
- Low accuracy for handwriting detection
- Imprecise detection of special characters and checkboxes
The solution – Vision bot
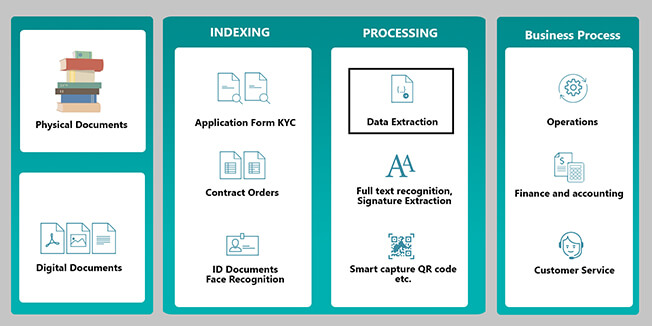
Figure 1: Vision Bot Architecture
We built an IP that simplifies data extraction, indexing, text-based search, quality check and QR code capture, and integrates with BPM systems (shown in Figure 1). We will dive deep into the data extraction process for the purpose of this blog.
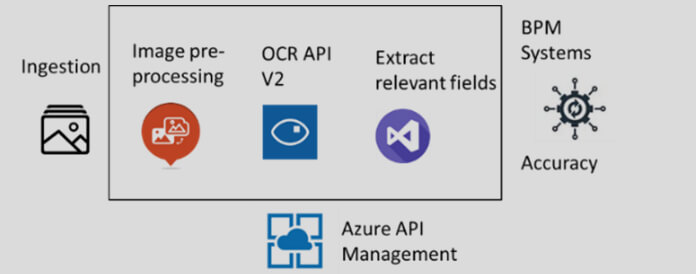
Figure 2 represents the data extraction process that is hosted as an API, using Azure API management.
Image ingestion
The bank had all its images lying on an on-premise server. Data had to be transferred using batch processing. Real-time hits to the API were also accommodated. Currently, the OCR API can process up to 10 documents per second in real-time, which is a challenge with OCR throttling. Multiple APIs can be used alongside a load balancer to overcome this. Since we already had a set of images resting on the server, our platform could digitize up to 100 documents per second using custom scripts that run on the client location and save the results on the database, using custom batch processing. An operational challenge we faced was that this server was not always accessible to us. There was a limitation on the number of server hits expressed by the bank, thus slowing down the process. Another concern with ingesting images to the API pertained to authentication. Since these are confidential images, it is essential to ensure that the traffic to the API is secured. We used the Azure API Gateway, which handled authentication, API monitoring and version management securely.
Image pre-processing
Once the authorized image was on our API, it underwent a series of processing steps before it hit the Azure OCR API.
- Resizing and fixing the pixel resolution to be within the thresholds of the OCR API, caution was exercised to ensure that the image quality is not hampered
- Rotating and straightening text with respect to the vertical axis
- Binarization, as black and white images offer the best contrast and improve OCR output
- Using adaptive filters to remove noise
A potential challenge here can be removing complex noises, like watermarks. Custom algorithms can be designed for the same.
Using the OCR API
There are two ways to use the OCR API.
Method 1: The first way is to allow the processed image as a whole to undergo extraction and apply logic on the JSON output to detect the extracted fields. For our use case of KYC, one of the documents we had to consider was identity cards. Once a processed image is sent to the OCR API, the output would be bounding box coordinates paired with the extracted text, as aforementioned. Basic logical functions are applied to the output. For instance, in a passport, the logic would search for bounding box text that reads ‘Name,’ and applies coordinate geometry to detect the corresponding closest box on the right. The text in this bounding box is extracted and saved.
One of the challenges here pertains to misalignment in terms of printing the values right beside the printed field (as in case of Voter ID Cards), where the word ‘Name’ is sometimes printed slightly higher than the name of the individual. Implementing logic in such outlier cases becomes difficult.

Figure 3: Sample MRZ in a passport
Method 2: The second way is to train a Machine Learning (ML) model to identify the Machine-readable Zones (MRZs), the specific areas on the processed image on which we wish to detect text, filter these areas and only provide them as an input to the OCR API. The extracted JSON output would then directly provide the text we need. A relevant use case where this method is applicable is in passports, as shown in Figure 3.
Passports are standardized across the globe by the bottom-most MRZ region of passports, while the format of other fields like name, nationality, etc., could differ.
To train the ML model to pick out the MRZ in every image of a passport, various techniques, like Support Vector Machine (SVM) and Histogram of Oriented Gradient (HOG) can be deployed. Improved detection of MRZ is a topic of ongoing research. Another area where this is applicable is the forms that have both printed and handwritten text. The method allows a model to identify which zones are printed vs. handwritten, and then sends these zones to different APIs for extraction. It is worth noting that the output of OCR is directly proportional to the text density. Therefore, accuracies in the first method are better. Another challenge with MRZs is that to achieve good accuracy, we need thousands of samples to train the ML model – a factor that gets limited by the number of samples the customer can provide for the training.
For the bank’s implementation, we used the first method. We began testing the second for hand-filled application forms but noted that a general complexity about OCR lies in handwriting. The banking industry amasses thousands of hand-written documents and applications. For example, name and account number could be in block letters, whereas address and branch name could be in cursive letters. Although a high-quality output was obtained for block letter hand-written inputs, extraction of cursive writing was a challenge. Given the varying nature of handwriting and the unavailability of large data sets for machine training, the accuracy of the API tends to be lower than that of printed text. Improved handwriting detection is another topic of research.
Achieving accuracy and latency
We can measure the accuracy of the OCR API using two approaches – character-by-character comparison or word-by-word comparison. In our case, the word-level accuracy applied suitably, since the bank wanted to know how many fields, like name, date of birth and address, were extracted correctly.
The accuracy was measured by recording the number of fields edited by the bank workers (in the BPM) against the total number of fields extracted by the solution. We achieved a –
- Character accuracy rate of 95 percent
- Field accuracy level of 90 percent
Given that the bank had an accuracy rate of 85 percent when data was entered manually by human effort, the solution surpasses the existing process. It also eliminates the time taken in data entry, as the output is stored to the BPM within five seconds after the image hits API. The operators can now skip to the next step of cross-verifying and editing incorrect fields.
Data storage and security
The solution offers clients the option to delete images immediately after processing. It temporarily stores images in a cloud-based No-SQL Database- Cosmos DB. Data encryption at rest and transit is enabled across all resource components of architecture, and the keys are stored securely in the Key Vault. Therefore, the solution complies with the security and privacy requirements of the BFS sector. All Azure resources used are ISO compliant as well.
The outcome
With OCR, the best practices for building a holistic text extraction solution for BFSI customers are reaching new benchmarks. The implemented solution has resulted in increased operational efficiency and reduced customer onboarding time for the bank. Here are some metrics around the efficiency gained:
- Time for extraction of fields – Five seconds
- Processing time saved – 10 hours, against a two minutes average time for manual entry of every field
- Accuracy of an extracted field – Above 90%
What’s next?
A lot of customers are now asking if this can be implemented on their premises, for obvious concerns. We’re discovering how the API can be deployed via a container for the same, we intend to release a blog on this soon. Stay tuned for more!
To know more about the solution, click here.
To know more about Microsoft’s Vision API, click here.
Originally published on Microsoft blog artcicle